Review of Linear Regression
Suppose
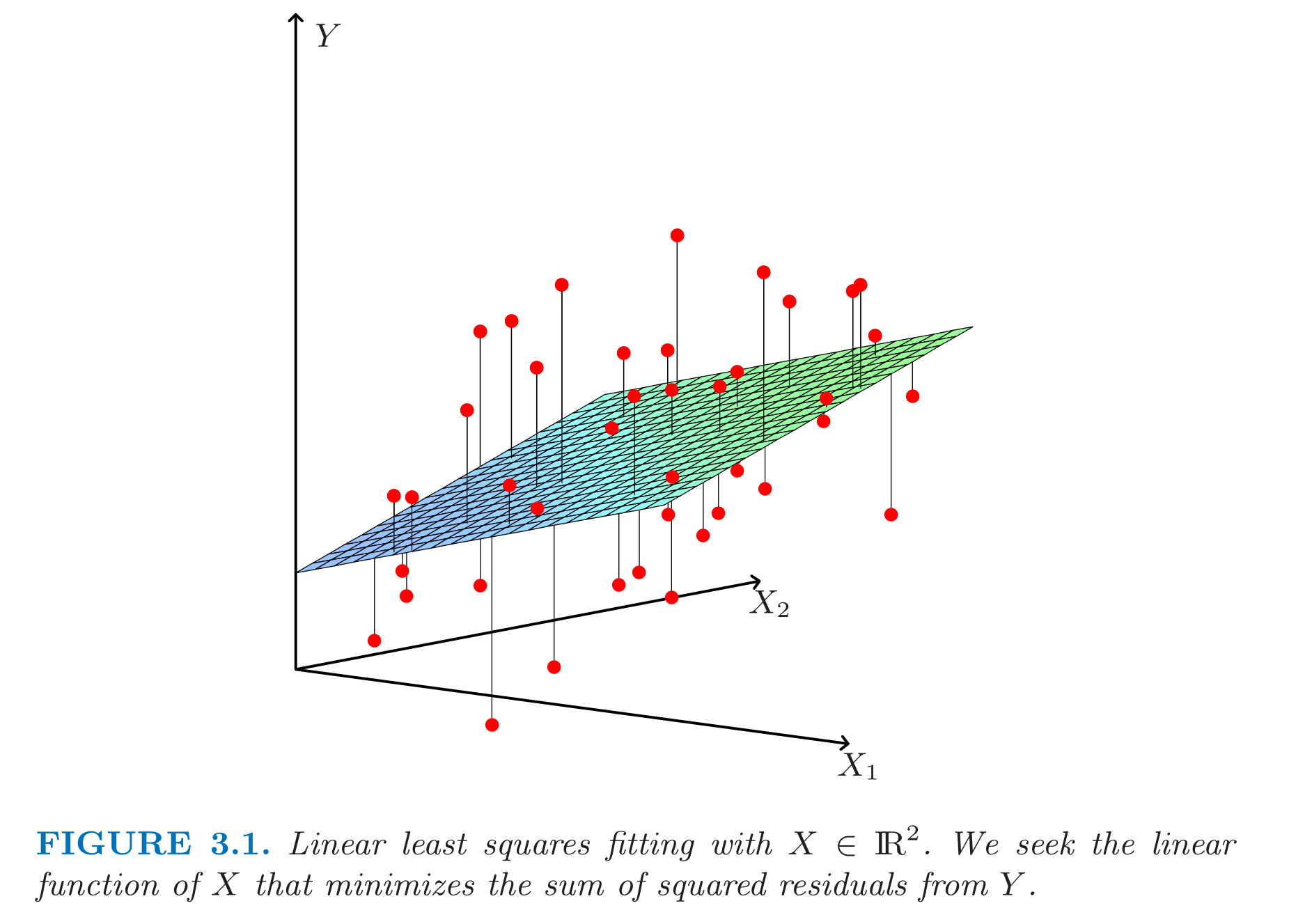
The second view is having each column (feature) as vectors in
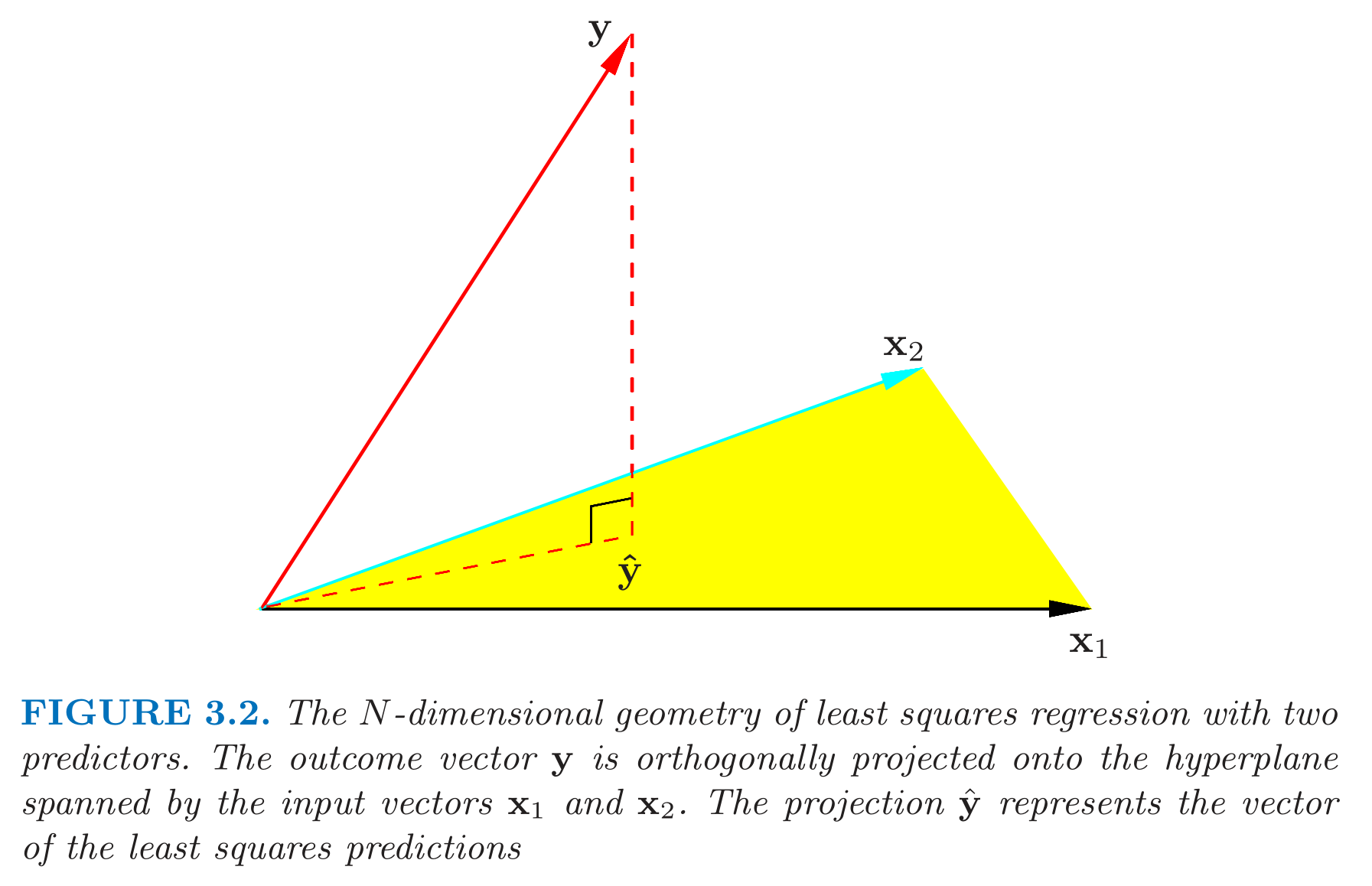
The orthogonal projection is done by the matrix
Statistics and Machine Learning
- Inference: Ask questions about
- Interpretability: Ask questions about
- Prediction: Guess
在传统的统计学中, 我们更关注inference, 需要对beta系数的variance, 显著性, confidence interval等有要求, 这个时候类似collinearity的问题就需要解决. 但是在prediction问题中, 我们则不需要考虑这个问题. 有时候即便model是错误的, 也并不影响其在某个范围有较好的预测性.
Linear Regression in Higher Dimensions
在homework中做过一个simulation. 当
由于OLS已经是Best Linear Unbiased Estimator, 在unbiased的估计量中, 已经给出了minimum variance. 我们为了降低整体的prediction error, 只能牺牲掉unbiased这个属性.
Bias and Variance
Bias: Error in the expectation of our estimator. Does not depend on the randomness of our particular training data realization, just the flexibility of our function. Making
more flexible usually decreases bias. Variance: Error from the variance of our estimator around its mean. Does not depend on the true function
! Tends to increase with the flexibility of , since a change in data has more effect.
Ridge Regression
To solve the problem of higher dimensions, and reduce the variance of the model by adding the bias, we can introduce a penalty term to the cost function. A cost function could punish more when coefficients are larger, and drives the coefficients much towards zero.
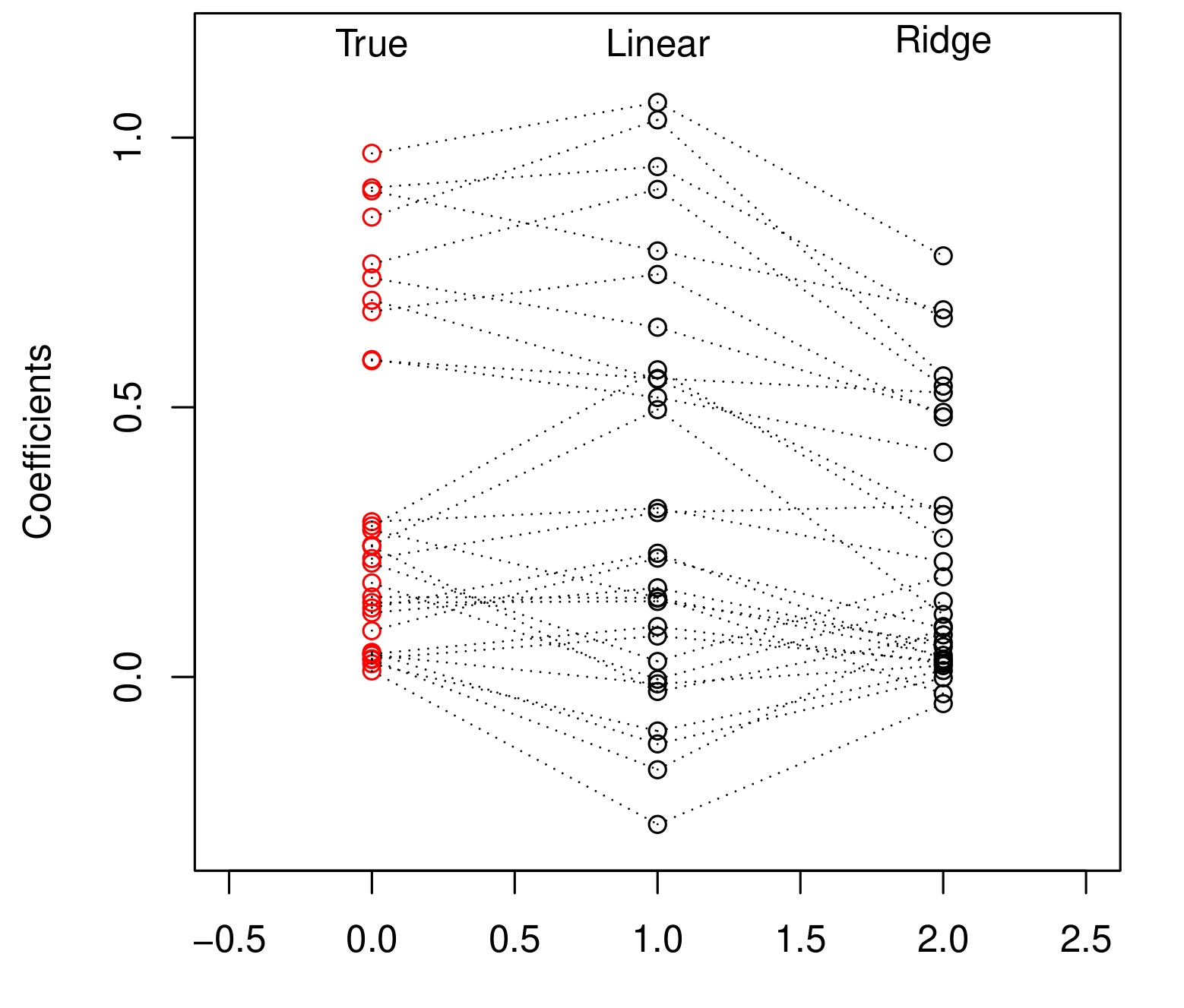
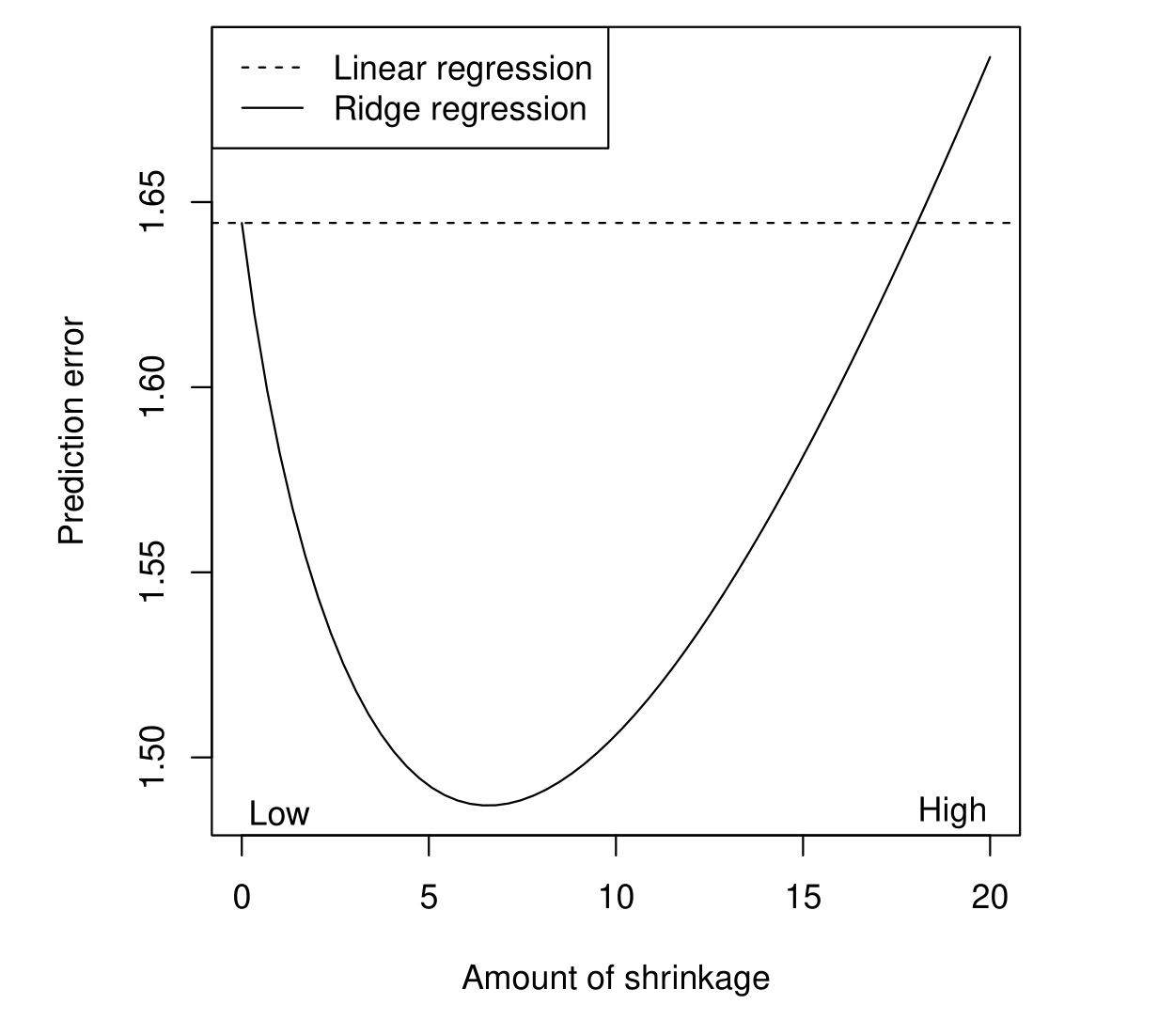
上面两幅图可以看到ridge对coefficients作了shrinkage, 从而降低model的variance.
- 当lambda = 0的时候, 等价于OLS
- 当lambda = infinity的时候, 所有的系数都趋近于0.
特别注意, 只要存在lambda, 那么一定会削弱model在training set上的MSE表现, 只是可能在prediction上表现更好.
Centering and Scaling
- Centering: to avoid penalty on the intercept term.
- Scaling: to avoid imbalanced penalty due to the magnitude of the coefficients.
一般而言, 我们不希望这个shrinkage effect发生在intercept上. 所以假如我们将intercept这一项从beta向量中剔除, 那么我们的目标function变成了.
如果
更重要的是, 在ridge中, 所有的predictors需要scaling. 原因是
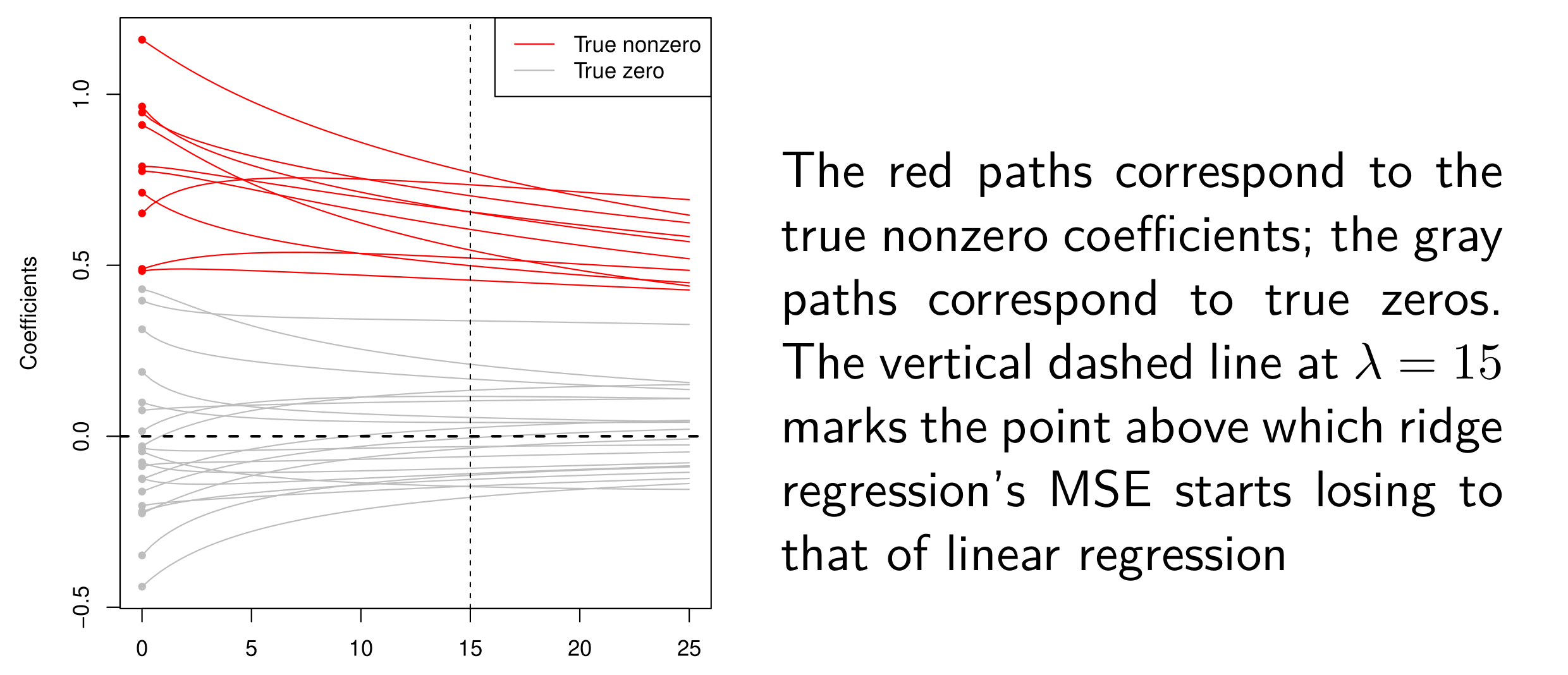
Ridge的缺陷也很明显, 上图表示两类coefficients, 一类是true value = 0, 另一类是nonzero. Ridge的penalty大部分作用在了那些nonzero的coefficients上, 当lambda逐渐增大的时候, 我们关注的coefficients收到了很大的影响, 但是这些本该是zeros的coefficients基本停滞了.
Lasso
Lasso adds a
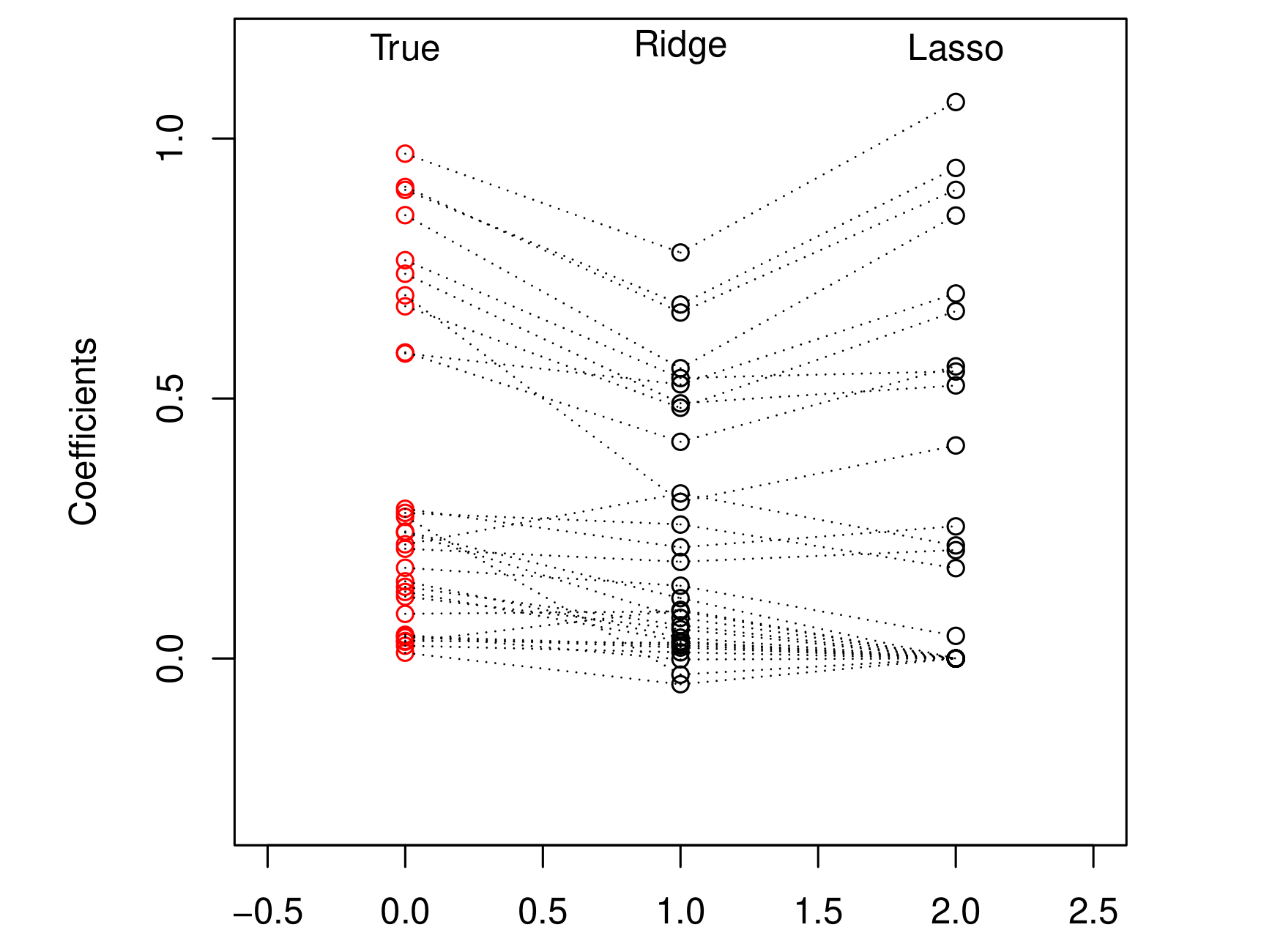
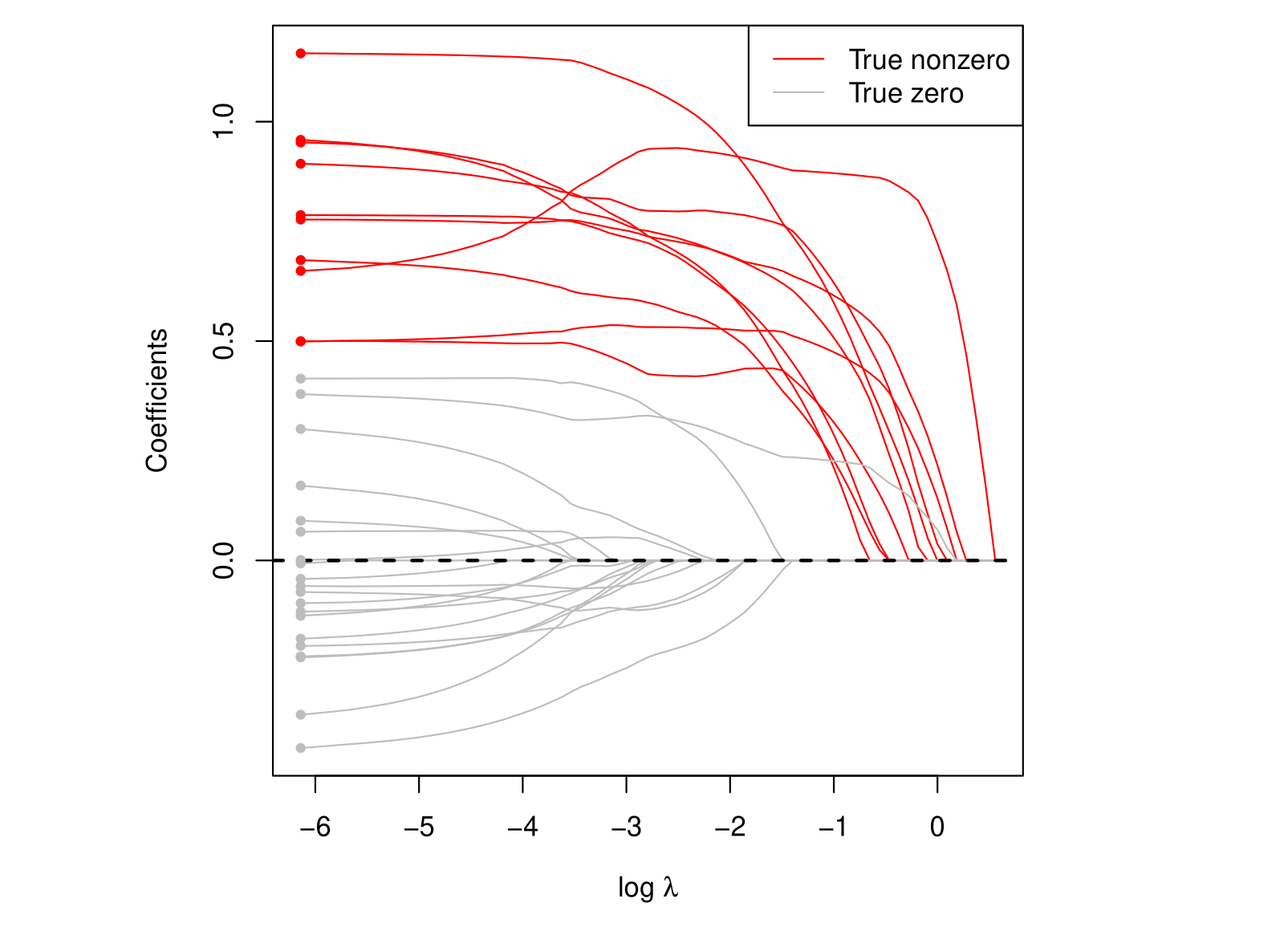
我们发现, 那些true values = 0的coefficients确实被压缩到了0, 这是我们愿意看到的结果. 我们将这种一部分coefficients变成零的情况,叫做sparsity。这有助于帮助我们得到以下特性,
- interpretability - understanding
- measure few things in the future, lower computation costs
- Know the underlying data. What features are useful?
和之前的ridge regression一样, 我们也需要做centering和scaling.
Ridge and Lasso Comparison
To understand further why different penalty forms can lead to different behaviors, think about the following simplified problem. If we put
Ridge has a direct solution by taking the derivatives. The size of beta, compared with OLS betas, are smaller, and can never be zero.
For Lasso,
这个表达式求导之后, 会得到一个分段函数. 当